Es passiert ja tatsächlich (wenn auch zugegebenermaßen ziemlich selten), dass ich gefragt werde, ob ich denn abends im Bett Wörterbücher lese. Die Antwort darauf lautet: nicht sehr oft. Ein Wörterbuch, das ich tatsächlich schon abends im Bett durchgeblättert habe, ist das Duden-Bildwörterbuch von 1935. Das ist mal wirklich aus verschiedenen Gründen ein spannendes Buch – mit kuriosen, absurden, amüsanten und durchaus auch verstörenden Abbildungen. Es ist daher an der Zeit, diesem Wörterbuch einen Beitrag zu widmen.
Erschienen ist das Wörterbuch, wie gesagt, 1935 – zwei Jahre nachdem Hitler und die NSDAP an die Macht gekommen waren. Diese gesellschaftlichen und politischen Umstände machen sich auch im Wörterbuch bemerkbar, wenn etwa unter „Wehrverbände“ SA- und SS-Männer mit typischen Utensilien, Fahnen usw. abgebildet werden; wenn etwa unter „Jugend“ neben den Pfadfindern und den Wandervögeln auch die „nationalsozialistische Jugend“ portraitiert wird; wenn unter „Grußformen“ der „Deutsche Gruß“ abgebildet ist; wenn an unterschiedlichen Stellen immer mal Hakenkreuze auftauchen. Aber spannend sind auch und gerade andere Abbildungen, die nicht unmittelbar Bezug zum Nationalsozialismus haben, sondern weitere Aspekte zeigen, denen man alleine aufgrund ihres Vorhandenseins im Wörterbuch dann ja gerne auch eine zeitgenössische Relevanz zusprechen möchte.
Beispielsweise teilt sich die Abbildungen zu den „Grußformen“ eine Seite mit einer Abbildung zum Thema „Rauferei“; versehen mit Erläuterungen wie „9 gibt 8 einen Fußtritt (Tritt) ins Gesäß (in den Hintern) und holt zu einem Schlag (Hieb) mit dem abgebrochenen Stuhlbein a aus“:

„Die Rauferei“ aus Duden-Bildwörterbuch (1935)
Man beachte auch die dezent an der Wand verteilten Geweihe. Wie aus dem Bauerntheater.
Einen Einblick in den damaligen Schulunterricht bietet die folgende Abbildung, inklusive Rohrstock (5), Spucknapf (11) und „Eckensteher“ (10):

„Die Schulstunde“ aus Duden-Bildwörterbuch (1935)
Deutlich moderner war man da schon in der Architektur – das Bauhaus lässt grüßen:
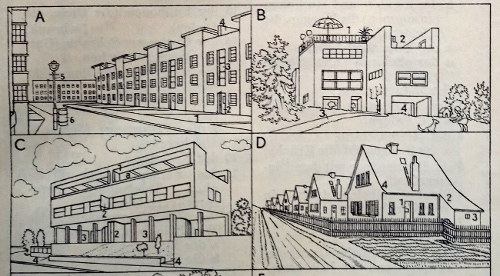
„Haustypen“ aus Duden-Bildwörterbuch (1935)
Im Inneren der Häuser war dann aber doch vieles anscheinend noch eher altbacken, der Abbildung zur „Diele“ nach zu urteilen:

„Die Diele“ aus Duden-Bildwörterbuch (1935)
Man beachte auch hier wieder die Geweihe an der Wand – neben dem modernen „Wandfernsprecher“ (22).
Nicht alles aber ist so harmlos; so ist zwischen den Themen „Rechtspflege (Justiz)“ und „Vorkriegsuniformen I“ eine Bildtafel zum Thema „Folter und Hinrichtung“ abgebildet, die allerlei Unschönheiten kompakt versammelt (u. a. die Verbrennung einer „Hexe“ (D 7)):

„Folter und Hinrichtung“ aus Duden-Bildwörterbuch (1935)
Apropos „Vorkriegsuniformen“: Dem Thema Kriegsführung und Militär wird verhältnismäßig viel Platz eingeräumt. Mehr als 20 Bildtafeln beschäftigen sich mit Themen wie „Schießausbildung“ (4 Doppelseiten!), „Manöver“, „Stellungskrieg“, „Seekrieg“ oder „Kasernenwesen“ (dazu die folgende Abbildung).

„Kasernenleben II“ aus Duden-Bildwörterbuch (1935)
Unter anderem zeigt die Abbildung den Grundriss der Aufstellung einer Schützengruppe (A, C) und so ziemlich alles, was zu einem „leichten Maschinengewehr“ gehört (B).
Faszinierend sind dann wiederum Abbildungen unter „Manöver: Der Nachrichtendienst“ wie die Brieftaube mit Fotoapparat und der „Meldehund“ mit Gasmaske:
 |
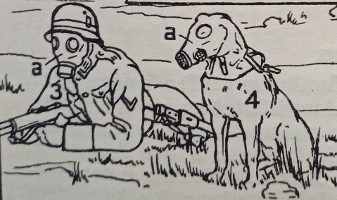 |
| Beide Abbildungen: „Der Nachrichtendienst“ aus Duden-Bildwörterbuch (1935) |
In der zweiten Auflage dieses Bildwörterbuchs, die 1958 erschien, ist von diesen über 20 Militär- und Kriegsabbildungen übrigens nicht eine einzige übernommen worden. 13 Jahre nach dem Ende des Zweiten Weltkriegs wird die Militärthematik komplett ausgeklammert und mehr oder weniger das einzige, das daran erinnert, ist dann ein „Soldatengrab“ auf dem Friedhof.
Aber auch für die Tiere waren es schon damals keine rosigen Zeiten, wie abschließend die Abbildung zum „Schlachtviehhof“ mit „Schlachtmaske“ (B 2a) bzw. „Schussmaske“ (C 1) zeigt, anhand der man sich dann bildlich vorstellen kann, wie es für die Kuh zu Ende geht:
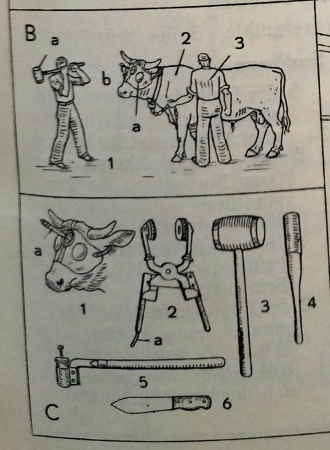
„Das Schlachten“ (B) und „Schlächtergeräter“ (C) aus Duden-Bildwörterbuch (1935)
Mit solchen Abbildungen hat mich dieses Wörterbuch komplett für sich eingenommen. Ein weiteres zeitgenössisches Wörterbuch, der Sprach-Brockhaus von 1935, der sich ebenfalls als „Bildwörterbuch“ bezeichnet (der aber eigentlich ein relativ unspektakuläres alphabetisches Bedeutungswörterbuch ist, das zu manchen Einträgen auch ziemlich biedere Abbildungen aufführt), kommt da bei Weitem nicht ran. Das Duden-Bildwörterbuch von 1935 dagegen ist ein Buch, das man auch wirklich gut abends vor dem Schlafengehen noch anschauen kann.








{kind=link}